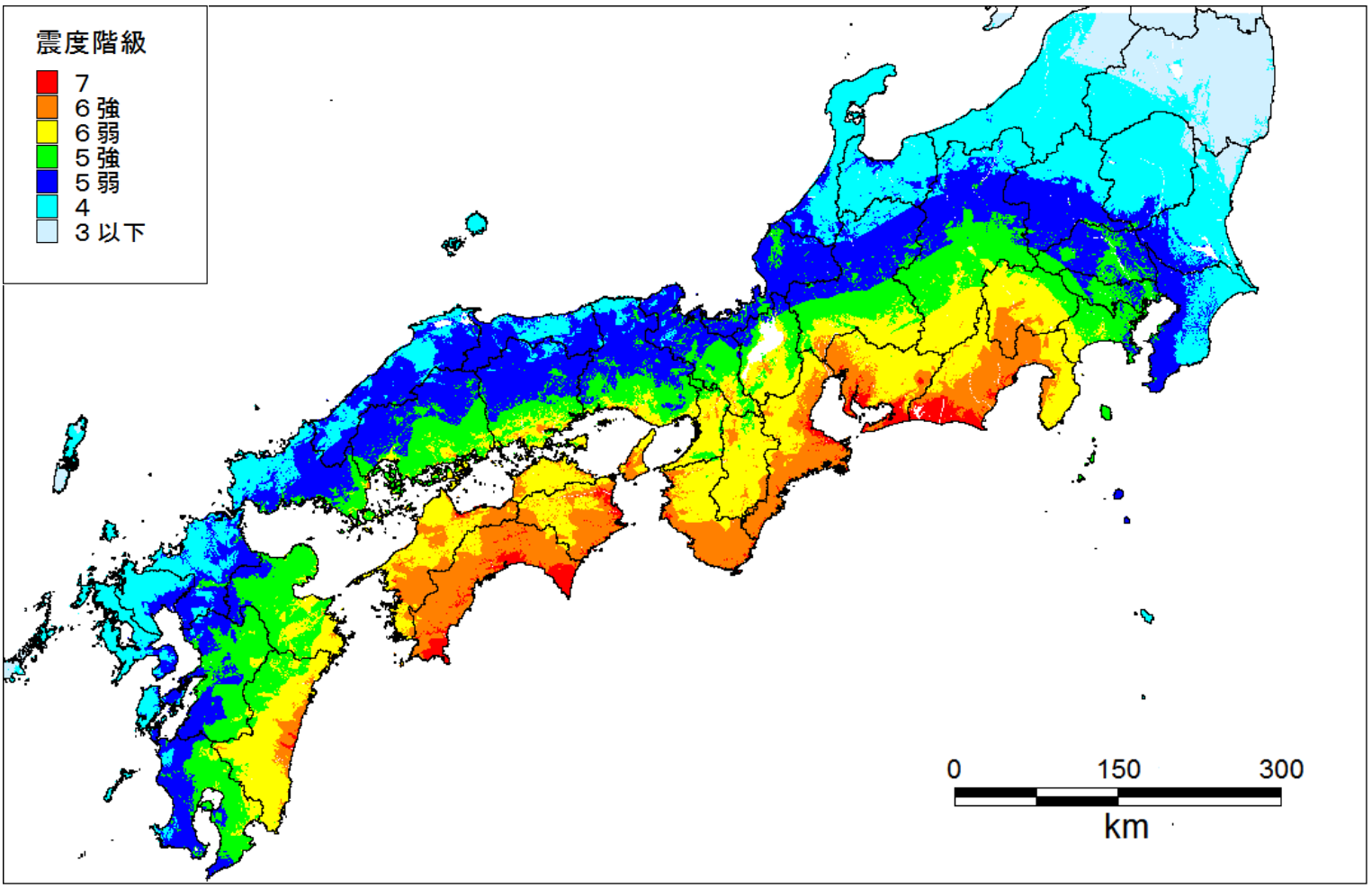
内閣府 南海トラフの巨大地震モデル検討会において、使用されていた震度分布・浸水域等に係るデータが公開されています。高潮推算や津波推算にも活用できるデータがあり、今回はそのデータのダウンロード方法や使い方について説明します。
1.データのダウンロード
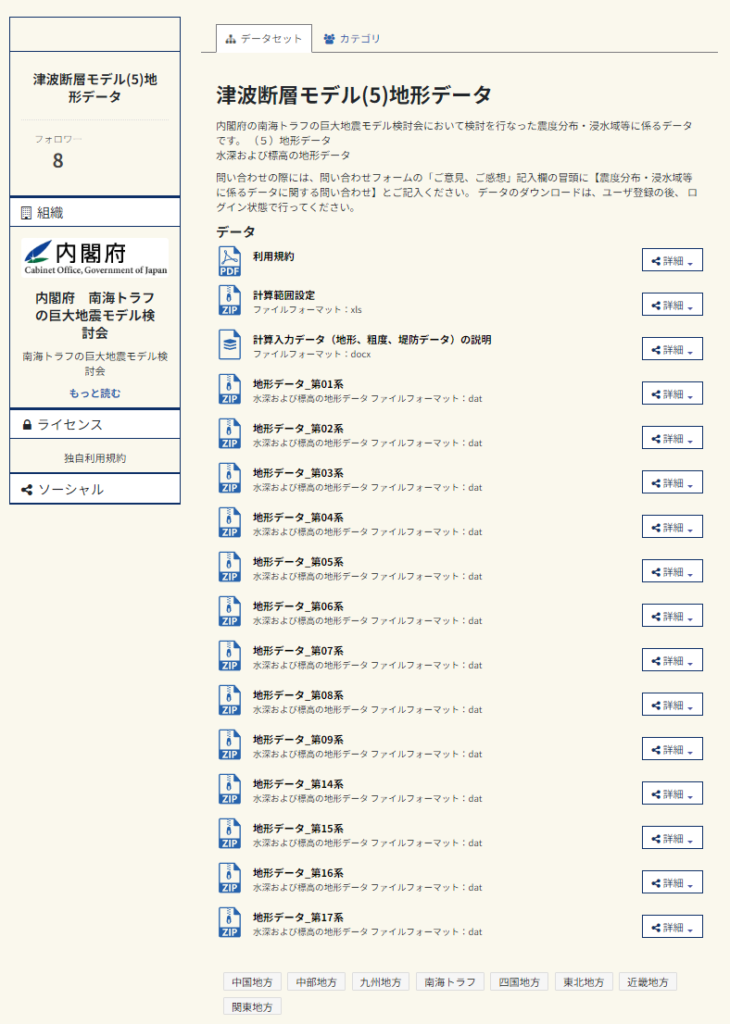
データのダウンロードサイトは「https://www.geospatial.jp/ckan/organization/naikakufu-01」となります。提供されているデータは地形データや粗度データ、堤防データなどがありますが、ここでは地形データを例とします。

データは平面直角座標系別で提供されています。各座標系のデータ範囲は「計算範囲設定」というエクセルに記載されています。各シートに各メッシュサイズのデータ範囲を示していますが、J列にはデータの列数(Y)、K列は行数(X)となっています。
ここでは7系(石川県・富山県・岐阜県・愛知県)を例として説明します。
2.データの処理・変換
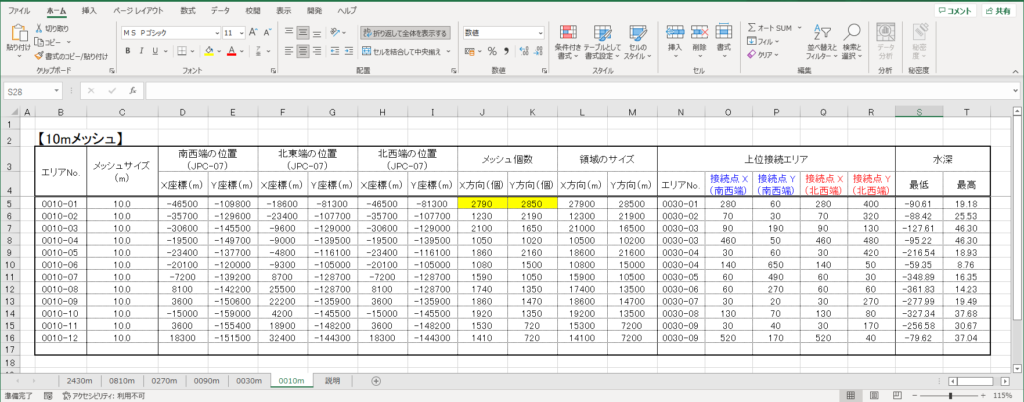
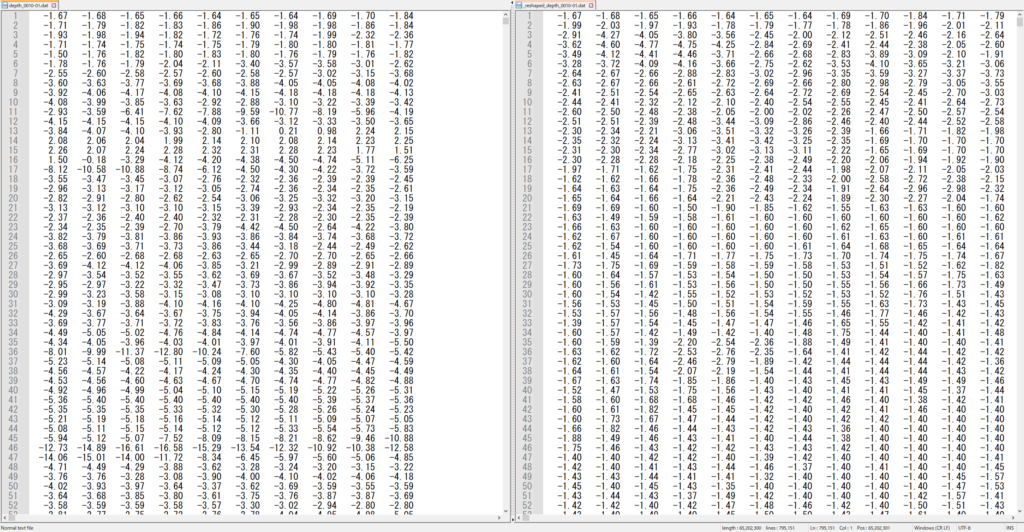
データ形式が?行×10列の形式となっているため、マトリックス形式に行列変換が必要です。
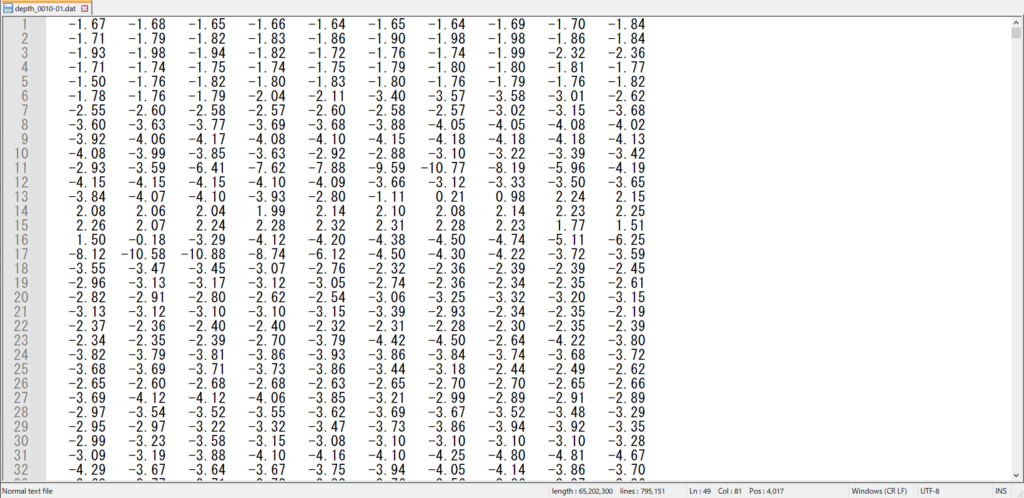
前記の「計算範囲設定_第07系.xls」より行列数を確認でき、黄色ハッチングの部分は10-01領域のXY方向のメッシュ数を示されています。
Pythonを使って行列変換します。使用するコードは下記となります。大量処理できるようにしていますが、pathのところで調整することで単独処理でもできます。
import numpy as np
import glob
import os
# データ格納のフォルダpathを修正することで一括処理。
path = r"D:\地形データ_第07系\depth_0010-01*"
flist = glob.glob(path)
for fname in flist:
dir_name = os.path.dirname(fname)
# ファイル名+拡張子の分割機能
base_name, ext = os.path.splitext(os.path.basename(fname))
print(f"現在処理中のデータは:{base_name}")
array = np.genfromtxt(fname, delimiter=[8]*10, names=None)
cols = int(input("変換後の列数【X方向(個)】: "))
array_reshaped = array.reshape((-1, cols))
new_fname = os.path.join(dir_name, f"_reshaped_{base_name}{ext}")
# fmtの所で出力形式を設定する。
np.savetxt(new_fname, array_reshaped, delimiter="", fmt="%8.2f")
print(f"{base_name}の個別変換終了しました。")
print("【全て】変換終了でした")
input形式で変換後の列数を入力すると変換が終了となります。変換前後の比較は下記の図のようです。
変換成功しましたね。
3.変換後のデータのコンター図作成
変換後のファイルを用いてコンター図を描くプログラムも共有します。
名古屋港の形は何となく分かります。
import matplotlib.pyplot as plt
%matplotlib inline
rows, cols = array_reshaped.shape
x = np.arange(0, cols)
y = np.arange(0, rows)
X, Y = np.meshgrid(x, y)
Y_flipped = np.flipud(Y)
plt.contourf(X, Y_flipped, array_reshaped, levels=20, cmap='viridis')
plt.gca().set_aspect('equal', adjustable='box')
plt.show()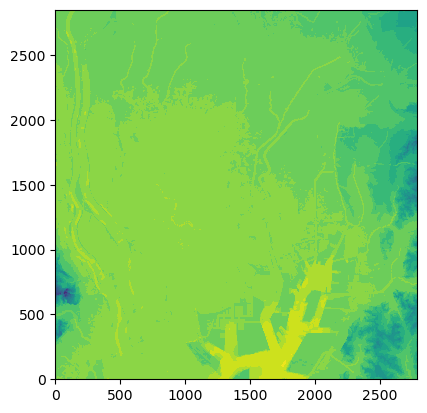
以上。


コメント